

科技日报记者 马爱平
随着大模型技术的爆发和快速发展,各种参数、系列的模型层出不穷。它们之间有差异吗?不同的大模型是否有各自的“天赋”?
近日,中国电信人工智能研究院(TeleAI)科研团队在5个开源异构数据集上对近50个主流开源大模型测试了文本无损编码压缩增益,并统计实验中模型推理的计算开销。结果显示,不同系列模型要实现同等文本无损编码压缩增益,所需计算开销有明显差异。而同一系列模型,尽管尺寸各异,但文本无损编码压缩增益与计算开销的比值(即大模型的信容)往往保持高度一致。
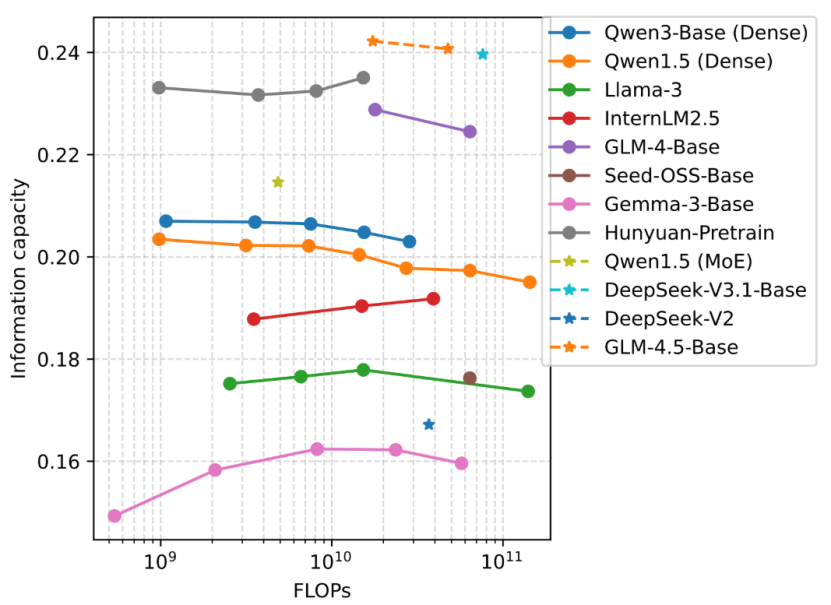
信容是信息与模型参数量的比值,用于表示模型内存储的知识密度。如果把模型比作海绵,信息比作水,那么信容就如同海绵的吸水效率,水吸得越多、越快,说明模型越“聪明”。信容为比较不同架构和参数大模型的推理效率提供了量化依据,可用于高效评估不同预训练数据、模型架构和超参数的优劣。基于信容评估指标,通过对同源小尺寸模型的测试,就能预测大尺寸模型的性能表现,从而加速模型的开发和迭代。
科研团队以智传网理论框架为基础,通过“信容评估指标”对大模型的效率进行标准化度量。该指标基于“压缩即智能”的深刻洞察,结合压缩性能与推理复杂度来定量评估模型效率,不仅能揭示模型在单位计算代价下产出的智能密度,还能在复杂的通算融合网络中为“算”与“传”的资源最优配置提供理论依据。
随着大模型推理负载消耗越来越多的计算资源和能源,如何准确评估大模型的推理效率吸引了学界越来越多的关注。专家表示,科研团队通过信容指标让跨架构和尺寸的大模型效率评估成为可能,并能有效指导模型的预训练和高效部署。这项研究不仅为大模型的绿色低碳发展提供了定量标尺,也为未来通算融合网络的设计指明了方向。随着边缘智能的快速发展,智传网的“端-边-云”分层网络将在不远的未来取代传统的以云上服务器为中心的计算范式,实现更精准的模型选型与算力分配。
目前,该研究的相关代码与数据已在相关平台开源。
(受访者供图)
 网友评论
网友评论
















