高远 科技日报记者 王春
4月28日,商汤科技正式发布并开源日日新SenseNova U1系列原生理解生成统一模型,该模型基于商汤今年3月自主研发的NEO-unify架构,实现了单一模型架构上多模态理解、推理与生成的统一,凭借创新技术突破,为多模态AI发展及产业落地提供了全新路径,助力多模态AI技术加速普惠。
商汤科技相关负责人表示,在逻辑推理与空间智能等方向上,SenseNova U1能够深度理解物理世界的复杂布局与精细关系;在未来,它还能为机器人提供具身大脑,实现在单一模型闭环内完成从复杂环境感知、逻辑推演到精准任务执行的全过程,为推动技术与产业发展提供重要基础与关键引擎。
据介绍,NEO-unify架构摒弃了主流的拼接式,去除了视觉编码器(VE)和变分自编码器(VAE),重新构建统一的表征空间,并且深入融入每一层计算中,从而实现从模态集成向原生统一的范式跨越。这使得SenseNova U1系列模型能够将语言与视觉信息作为统一的复合体直接建模,实现语言和视觉信息的高效协同,让理解与生成能力同步增强,在保留语义丰富度的同时,维持像素级的视觉保真度。
形象地说,传统多模态模型就像一个由“说不同语言的人组成的工作组”,有人专门处理图像、有人专门理解文字,信息传递过程中难免出现等待、误解和损耗,往往需要通过堆大参数来弥补不足。而SenseNova U1更像是一个“全能大脑”,能在同一套“思考方式”里直接处理图像、文字等不同信息,无需中间转译,让信息流转更快捷、理解更直接、生成更高效。
此次开源的轻量版系列,包含基于稠密骨干网络的SenseNova-U1-8B-MoT与混合专家骨干网络的SenseNova-U1-A3B-MoT两个规格,已在GitHub、Hugging Face等社区开源。在多项基准测试中,该系列模型不仅在图像理解、生成与编辑等领域达到同量级开源模型SOTA水平,仅凭8B-MoT的较小规格,就能达到甚至超越部分大型商业闭源模型。
值得注意的是,凭借NEO-Unify架构优势,SenseNova U1在业内首个实现连续性的图文创作输出。只需要单次单模型调用,就能输出更高质量的作品,相比传统范式,实现了效率的大幅提升。其原生图文理解生成能力,能将图像和文本底层融合信号完整保留在上下文中,区别于过去多模型串联的勉强实现方式,让图像间风格保持高一致性。
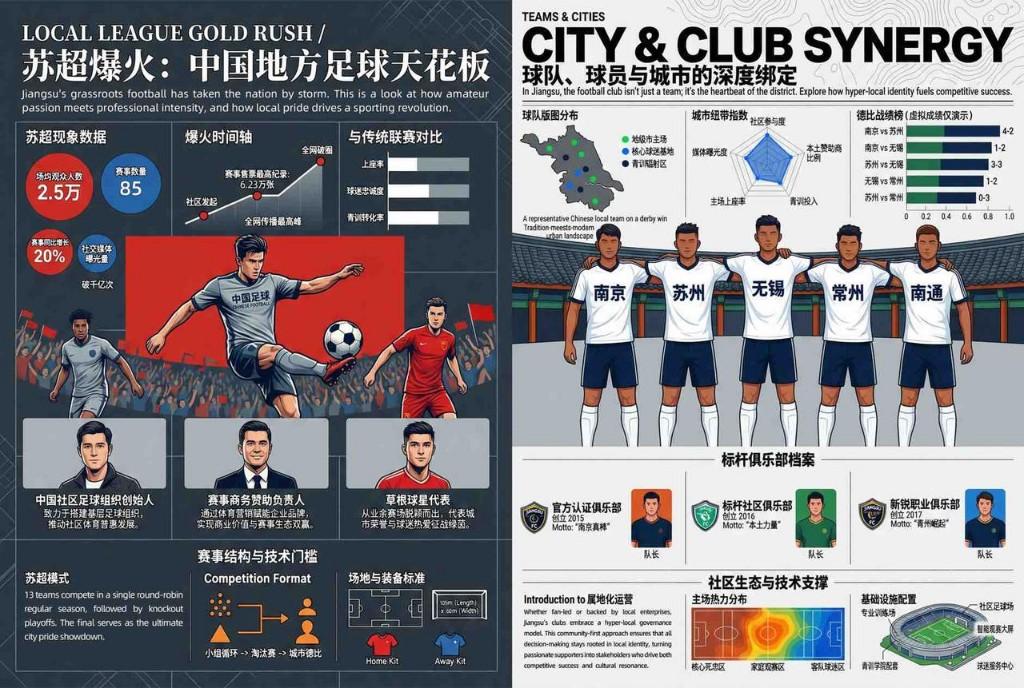
据悉,在绘制钢铁侠图案时,模型可从扫描草稿出发逐步连续创作,精准保留每一步的结构与细节;生成五分熟牛排菜谱时,能分步规划并输出对应图示,各步骤画面一致性极高。更值得一提的是,该模型在复杂信息图生成任务中表现出商业级水准,有效解决了传统AI生成图文时文字乱码、扭曲的痛点,在保留语义丰富度的同时,维持像素级视觉保真度。
 网友评论
网友评论