

科技日报记者 杨雪
近日,北京大学科研团队在国际上首次实现后摩尔新器件异质集成的多物理域融合傅里叶变换系统,提出了突破当前傅里叶变换系统速度与功耗瓶颈的关键技术,标志着傅里叶变换硬件架构实现从算法驱动走向器件物理域驱动的重大跨越。该成果1月9日发表于国际顶级学术期刊《自然∙电子》。

随着大模型、具身智能、脑机接口等新型计算场景不断涌现,对大吞吐、高精度、高并发、多种异构计算的要求愈发提高,传统硅基器件面临“微缩、功耗、存储”三堵难以逾越的高墙。摩尔定律已进入瓶颈期,以忆阻器、光电器件为代表的“后摩尔新器件”凭借独特的物理赋能计算特性,被视为突破算力与能效困局的最大希望。
尽管多种后摩尔新器件在矩阵乘加等简单线性算子上具有显著优势,但由于支持算子种类单一,无法适配实际应用中多样化的计算方式需求,这些前沿技术始终难以跨越“从实验室到市场”的鸿沟。可以说,拓展可支持的算子谱系不仅是后摩尔新器件芯片研发与实用化落地的“深水区”,更是我国实现底层算力突破必须啃下的“硬骨头”。在此背景下,科研团队长期在面向实际应用落地的后摩尔新器件算子谱系拓展攻坚,前期已突破多种复杂算子的后摩尔新器件多物理域电路与架构设计。
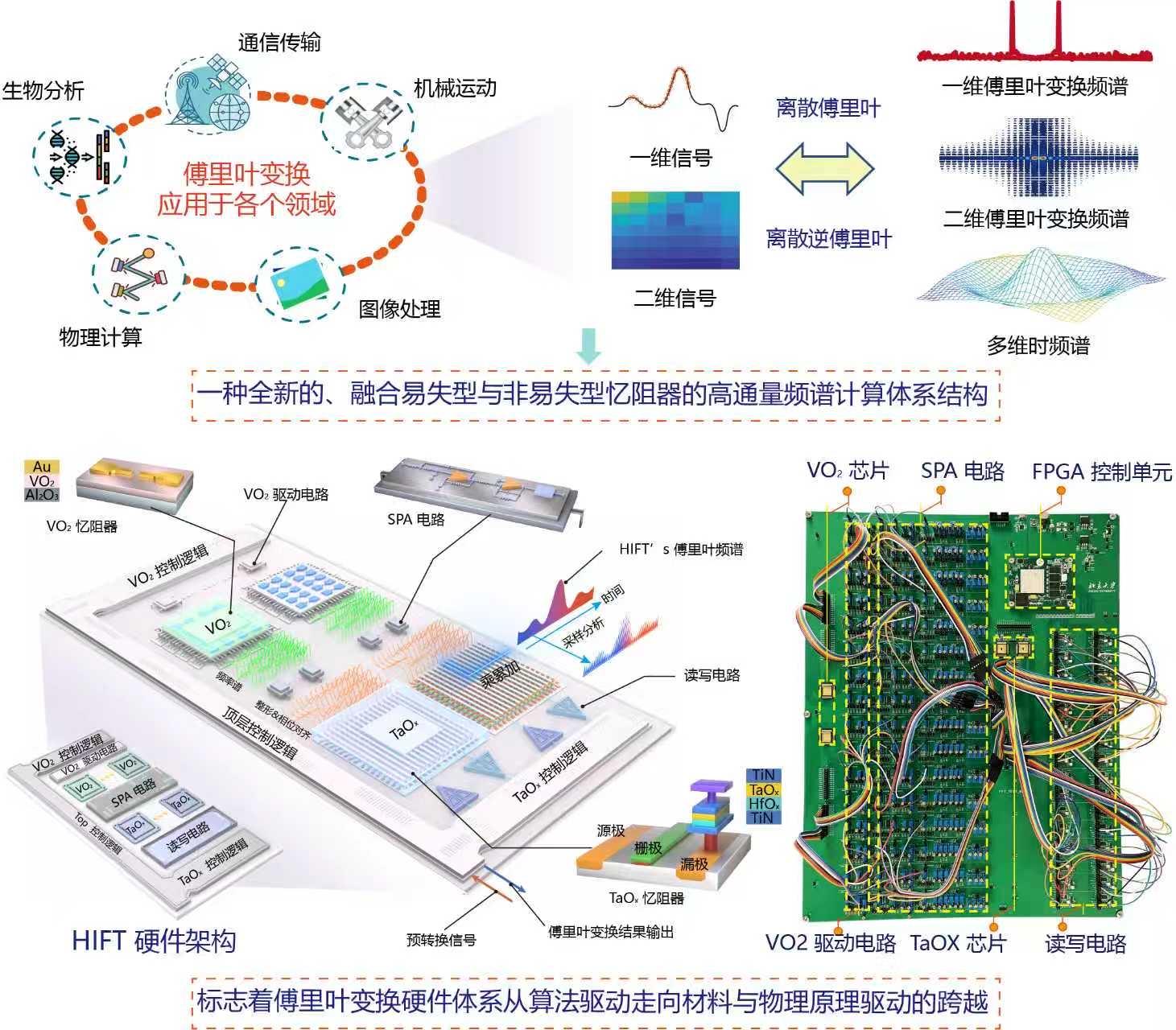
论文共同第一作者兼通讯作者、北京大学人工智能研究院研究员陶耀宇介绍,傅里叶变换作为AI领域的“底层引擎”,其核心功能是将复杂的信号(声音、图像、时间序列)转换为频率的语言。在人工智能中,这种能力被广泛应用于特征提取、降噪、压缩以及计算优化等方面。它是人工智能、通信系统、科学计算、脑机接口等海量实际应用场景中使用最为广泛的算子之一,也是后摩尔新器件实用化破题的关键抓手。科研团队创新地将易失性氧化钒器件与非易失性氧化钽/铪器件进行系统级异质集成,充分发挥了两类后摩尔新器件在频率生成调控与存算一体方面的互补优势,在保证傅里叶变换精度、降低计算功耗的前提下,可将吞吐率从当前100GS/s级别提升至500GS/s以上。
“这一新技术架构实现了高达99.2%的傅里叶变换精度,实验与仿真结果显示,其吞吐率最高可达504.3GS/s,相比目前最快的硅基芯片提升近4倍,能效提升达96.98倍,同时显著降低了存储与互连资源的消耗。”陶耀宇说。
论文通讯作者、北京大学集成电路学院杨玉超教授介绍,该成果聚焦突破后摩尔新器件的算子谱系扩展难题,有望解决当前众多前沿领域的低延迟、低功耗信号处理与计算需求。例如,在具身智能落地应用中突破端侧算力无法实时处理高并发、多模态信号的瓶颈;在脑机接口等生理信号处理领域,破解因信号处理功耗高导致患者需多次接受创伤性手术以更换硬件设备的痛点。
该成果落地应用有望让我国在新一代计算架构上实现超越,摆脱在传统硅基器件上受制于人的被动局面。随着后摩尔新器件多物理域计算架构的发展与应用,逐步实现全算子谱系覆盖,我国可能率先实现极低功耗、超小体积与超高算力的平衡,有望加速人工智能基础模型、具身智能、自动驾驶、脑机接口、生理检测、通信系统、信号处理等多个前沿领域技术的落地应用。
(受访者供图)
 网友评论
网友评论














